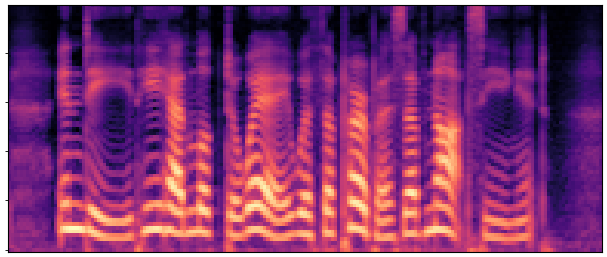
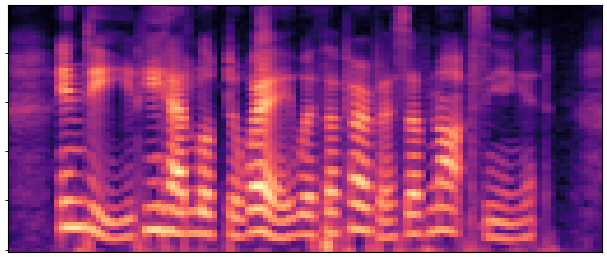
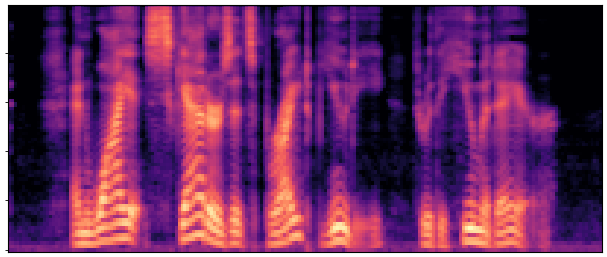
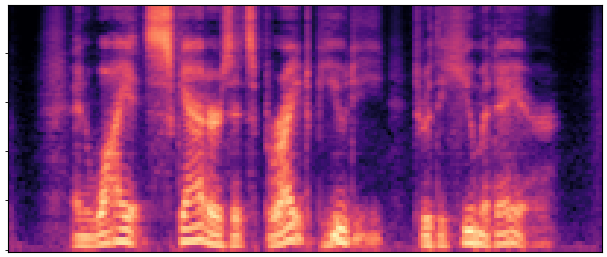
Abstract:
We propose a novel Token2Wav architecture that applies MeanFlow in a highly compressed latent space,
enabling true one-step generation with a single network evaluation.
Operating in the latent domain yields up to a 17× RTF improvement
over multi-step baselines with negligible quality degradation.
We further introduce refinement strategies—decoder-only and end-to-end joint fine-tuning—to mitigate latent mismatch.
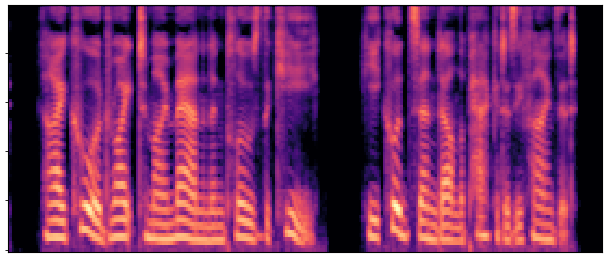
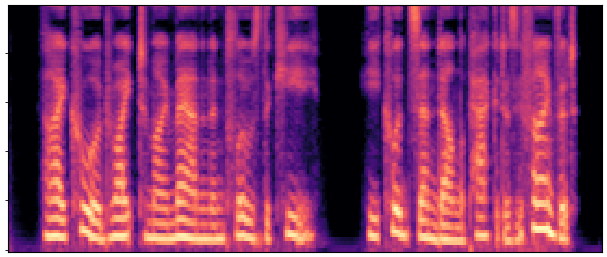
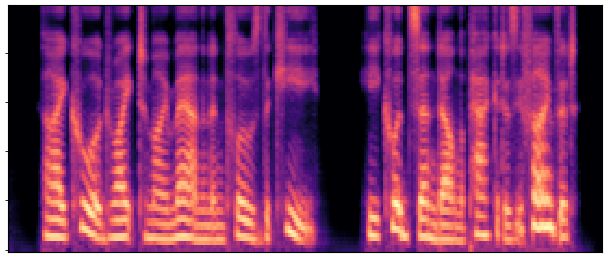
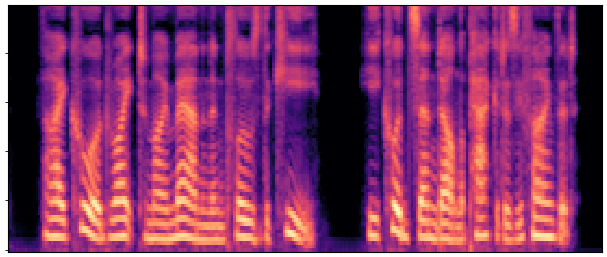
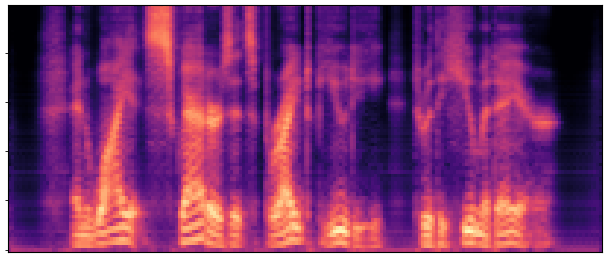
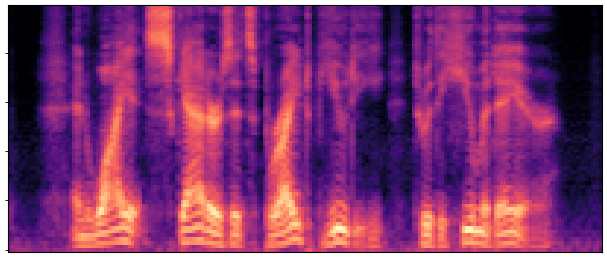
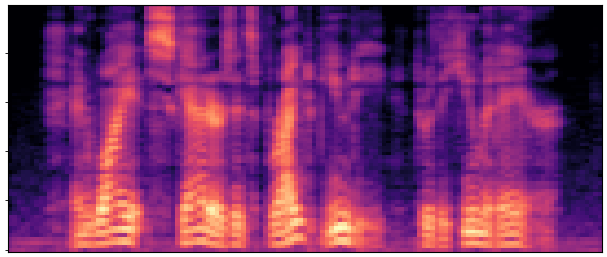
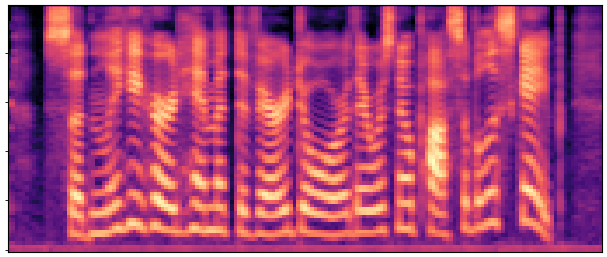
Main Results & Refinement Strategy Comparison
Evaluation on LibriSpeech test-clean. Our best system Joint-FT (D=24, 140M) achieves
17× faster RTF (0.0046 vs 0.0775) with competitive quality.
Refinement progressively improves quality: No-FT → Decoder-FT → Joint-FT.
| System |
Dim | WER(%)↓ | SpkSim↑ | UTMOS↑ | MOS↑ | RTF↓ |
| Baseline Token2Wav (10-step) |
— | 3.18 | 0.940 | 3.76 | 4.05±0.03 | 0.0775 |
| VAE reconstruction (oracle) |
24 | 2.14 | 0.966 | 3.67 | 4.10±0.04 | — |
| Ours: No-FT (D=24) |
24 | 3.52 | 0.931 | 3.11 | 3.35±0.03 | 0.0046 |
| Ours: Decoder-FT (D=24) |
24 | 3.43 | 0.931 | 3.43 | 3.70±0.03 | 0.0046 |
| Ours: Joint-FT (D=24) |
24 |
3.41 | 0.932 | 3.64 |
3.85±0.03 | 0.0046 |
|
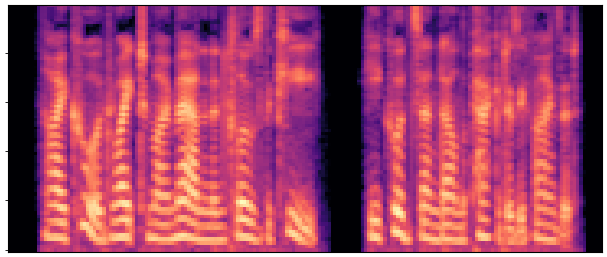
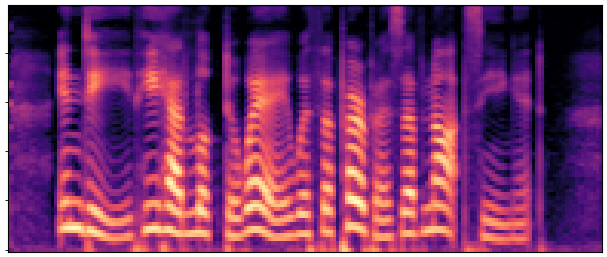
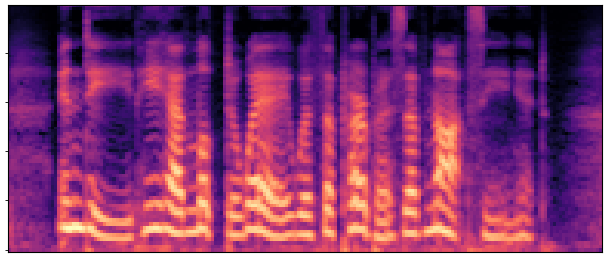
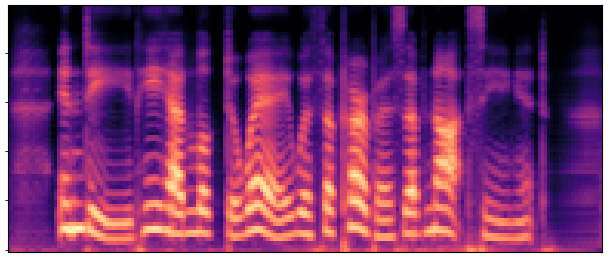
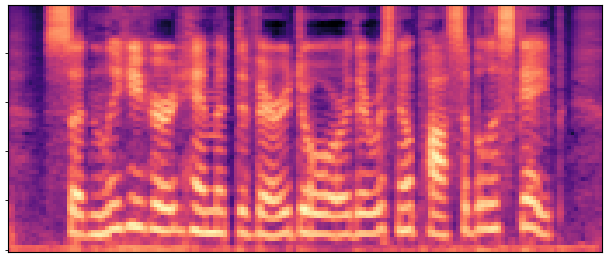
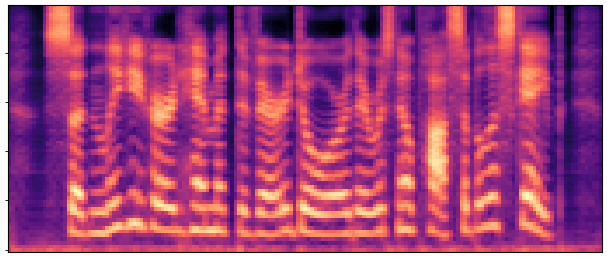
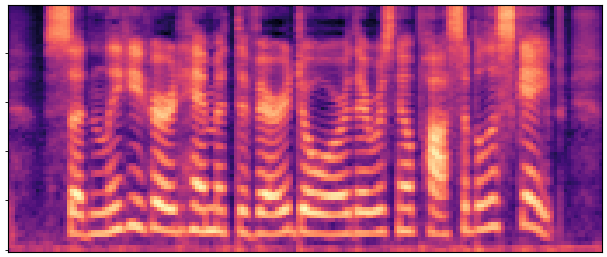
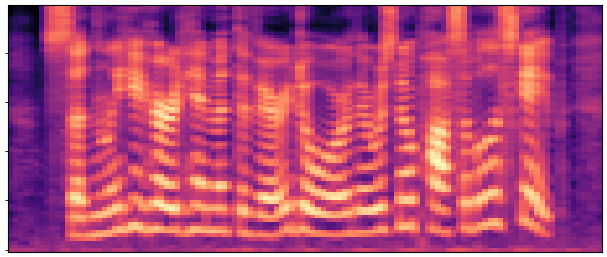
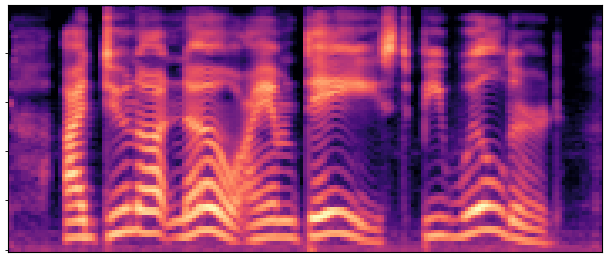
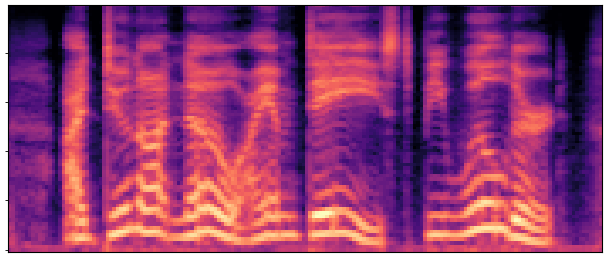
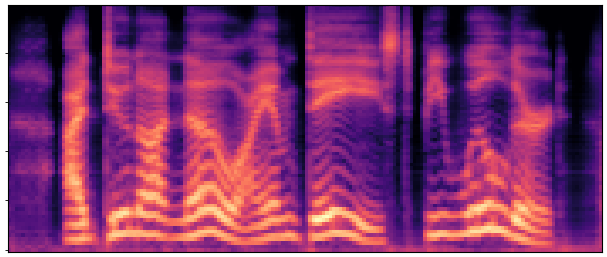
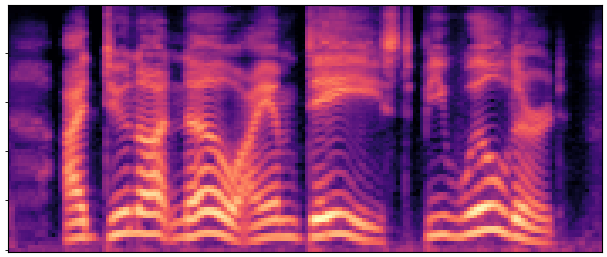
BaselineCosyVoice 10-step |
OursNo-FT |
OursDecoder-FT |
OursJoint-FT |
GTGround Truth |
| Sample 1 |
|
|
|
|
|
| Sample 2 |
|
|
|
|
|
| Sample 3 |
|
|
|
|
|
| Sample 4 |
|
|
|
|
|
| Sample 5 |
|
|
|
|
|
Ablation: Latent Dimensionality
Effect of latent dimension D on one-step generation quality (all with Joint-FT, 140M DiT).
Increasing D consistently improves all metrics; D=24 provides the best quality.
|
D=8Joint-FT |
D=16Joint-FT |
D=24Joint-FT |
GTGround Truth |
| Sample 1 |
|
|
|
|
| Sample 2 |
|
|
|
|
| Sample 3 |
|
|
|
|
| Sample 4 |
|
|
|
|
| Sample 5 |
|
|
|
|
Ablation: Model Size
Effect of DiT model size on one-step generation quality (all with Joint-FT, D=24).
Comparing the small (140M) and big model variants.
|
140MJoint-FT (D=24) |
BigJoint-FT (D=24) |
GTGround Truth |
| Sample 1 |
|
|
|
| Sample 2 |
|
|
|
| Sample 3 |
|
|
|
| Sample 4 |
|
|
|
| Sample 5 |
|
|
|